
Qlik Data Integration – Unified Data Integration Platform for Agile Enterprises
There is a growing demand from business users for integrated views of the freshest, most accurate data available. Having that, enables you to perform even more advanced analysis and use data for proactive decision-making. Data integration accelerates and automates data preparation processes for a real-time view of business performance which ultimately enables analytics tools to produce effective, actionable business intelligence. Qlik Data Integration (QDI) keeps you one step ahead, giving you the most recent data available, analytics-ready, without dependency of developers.
What is Data Integration?
Data Integration is the process of combining data from different sources to a unified view. This giving you access to the combination of data from different sources in one place, for use in applications and analytics. To ensure that the data is up to date, you need a Data Pipeline that enables a continuous flow of data.
“To lead in the digital age, everyone in your business needs easy access to the latest and most accurate data. Qlik enables a DataOps approach, vastly accelerating the discovery and availability of real-time, analytics-ready data to the cloud of your choice by automating data streaming (CDC), refinement, cataloging, and publishing” – Qlik
This means instant access to the same data you have in your internal systems, available for analytics and web-apps without the need for advanced development and coding.
For example:
- Analytics can be based on the latest available information – no more dependency on nightly updates of your data warehouse
- Web shops have instant access to the warehouse status – no need to open the internal network for external access.
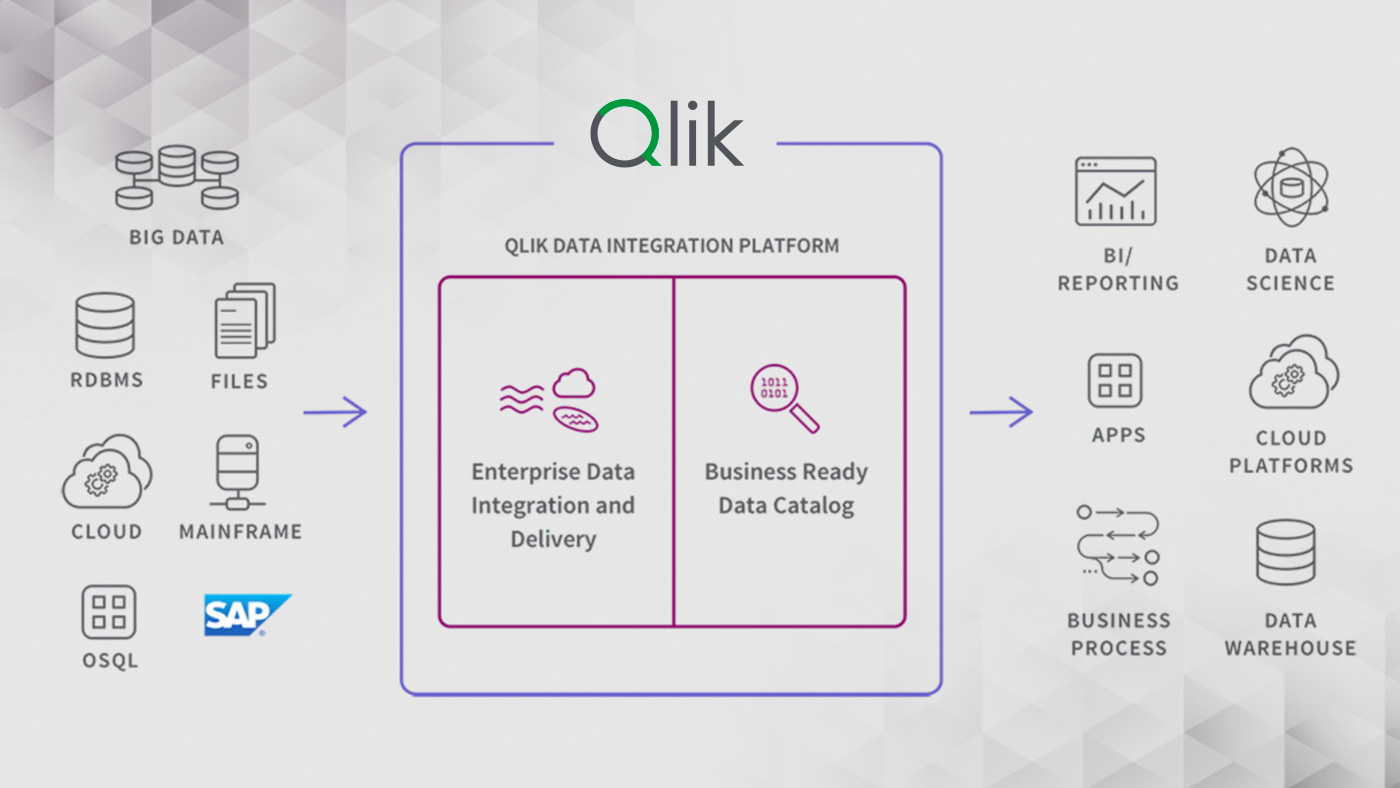
Qlik Data Integration provides all the tools needed to set up a real-time Data Pipeline including data ingestion, data replication, data warehouse and data lake automation. They also include a Data Catalog presenting the available data for self-service analytics in the preferred tool of choice. All this with an agnostic approach, meaning you can use it seamlessly with both internal databases as well as all the major cloud vendors.

The Qlik Data Integration Platform – From data sourcing to cataloging in one platform
Data Integration begins with the ingestion process, and includes steps such as ETL mapping, and transformation. The QDI includes all those processes within one platform that works seamlessly across on-premises and cloud environments.
- Qlik Replicate: Universal data replication and data ingestion.
- Qlik Compose: Accelerates creation of analytics-ready data structures.
- Qlik Data Catalog: Modern data management and cataloging.

Qlik Replicate
Qlik Replicate (former Attunity Replicate) offers optimized data ingestion from a broad array of data sources and platforms and seamless integration with all major big data analytics platforms. Replicate supports bulk replication as well as real-time incremental replication using CDC (change data capture). The unique zero-footprint architecture eliminates unnecessary overhead on your mission-critical systems and facilitates zero-downtime data migrations and database upgrades.
Qlik Replicate supports a broad range of different sources and platforms to enable you to synchronize data across on-prem and cloud environments. Those sources span from data warehouses to legacy systems, including platforms such as Oracle, SQL, Teradata, IBM Netezza, Exadata, AWS, Azure, Google Cloud, Cloudera, Confluent, SAP, and IMS/DB, DB2 z/OS and RMS.
What is CDC – Change Data Capture?
Change data capture refers to the process or technology for identifying and capturing changes made to a database. Qlik Replicate reads the database logs, constantly capturing all changes without the need of any installation on the source systems database server. This unique way enables real time replication without affecting the performance of the source database.
CDC eliminates the need for bulk load updating and inconvenient batch windows by enabling incremental loading or real-time streaming of data changes into your data warehouse. It can also be used for populating real-time business intelligence dashboards, synchronizing data across geographically distributed systems, and facilitating zero-downtime database migrations.
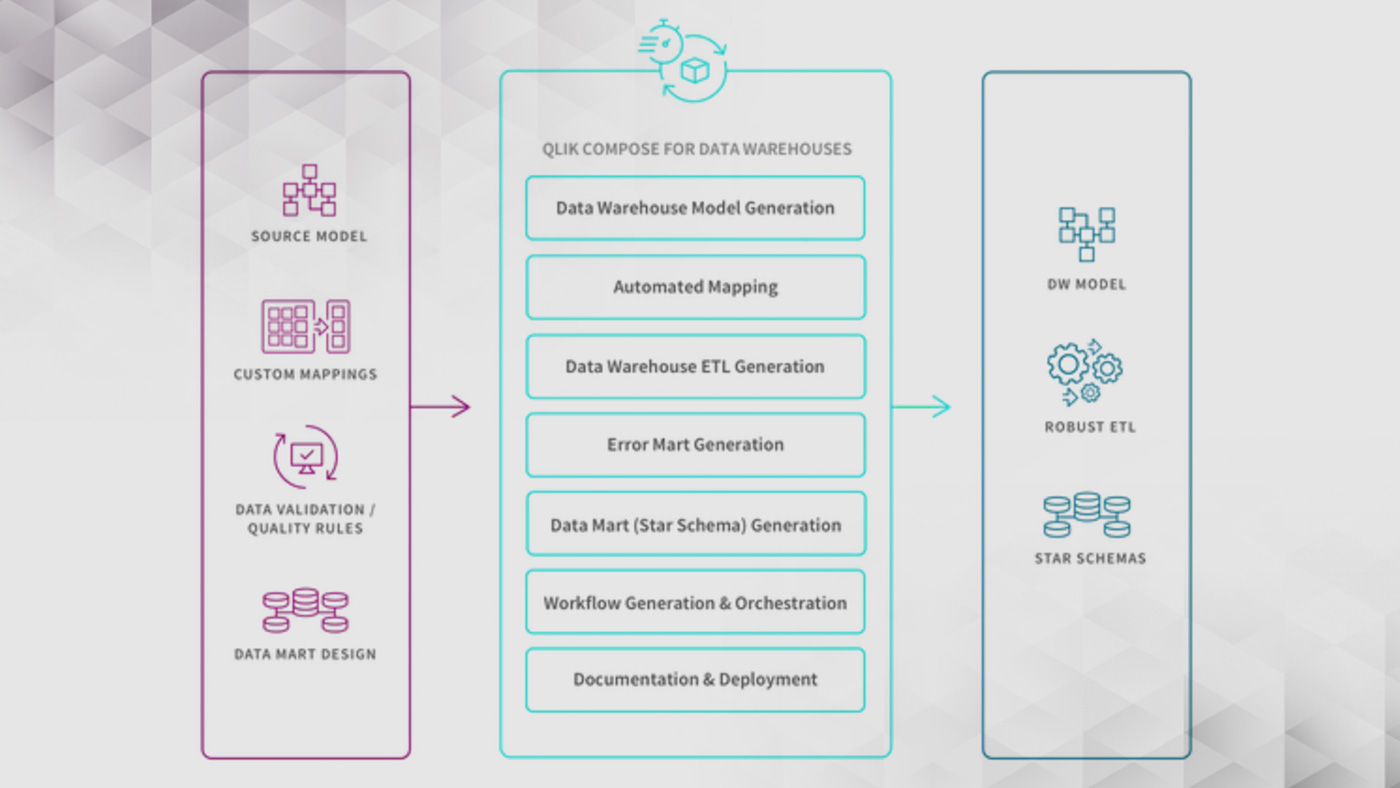
Qlik Compose
Qlik Compose automates and optimizes the creation and operation of data lakes and data warehouses. You can design your data warehouse or data lake and all transformations in an easy-to-use interface from source to data lake / warehouse and data marts without the dependency of developers, all whilst leveraging best practices and proven design patterns. Qlik Compose dramatically reduces the time, cost, and risk of data lake/warehouse projects, whether on-premises or in the cloud. Together with Qlik Replicate you can have your data lake / warehouse being updated constantly during the day without having to wait for large batch jobs during the night.
Qlik Compose is agnostic and works on a range of on-prem databases such as SQL Server, Oracle, DB2, SAP Hana and cloud platforms including Azure, Amazon, Google Big Query, Snowflake, Databricks, and data lakes, for example Cloudera or Hortonworks.
Qlik Catalog
Essential in Self-Service analytics, is that users not only have access to the available data, but also that they can find data and derive data lineage (the data origin, what happens to it and where it moves over time) and view the data quality.
Within Qlik Catalog, you can search for data sources, tables, fields, and descriptions with a shopping like experience based on access rules. It shows the data lineage, profiling, popularity, consistency, and quality as well as a sample of what’s available. You can select the desired data, instantly open it, and gain insights in your BI Tool of choice: Qlik, Tableau, or Power BI.
Ready to get started with Qlik Data Integration?
Get in touch and we can work through your options!
Jordy Wegman
BI Manager
jordy.wegman@climber.nl
+31 6 11 62 68 58
Tim Wensink
BI Consultant & Training Manager
tim.wensink@climber.nl
+31 6 57 49 78 55